关于目标序列的追踪,序列信号的控制。比例积分微分控制、最优控制、模型预测控制……
ROS的move_base先对地图进行全局路径规划,生成目标点(点位),再对运动时各个路径点进行局部轨迹规划,控制底盘来追踪目标点(轮速、航向)
graph LR t((Setpoint)) --> C[Controller] --> e((Effect)) --> env[/Unknown Environment/] --> i((Sense)) i --> C
PID控制器
FOC伺服详解(四)----PID和三环控制 - 知乎
(3 封私信) 串讲:控制理论:PID控制(经典控制理论) - 知乎
PID控制算法(PID控制原理与程序流程) - 暗影玄极 - 博客园
比例,积分,微分,具体是什么就略了
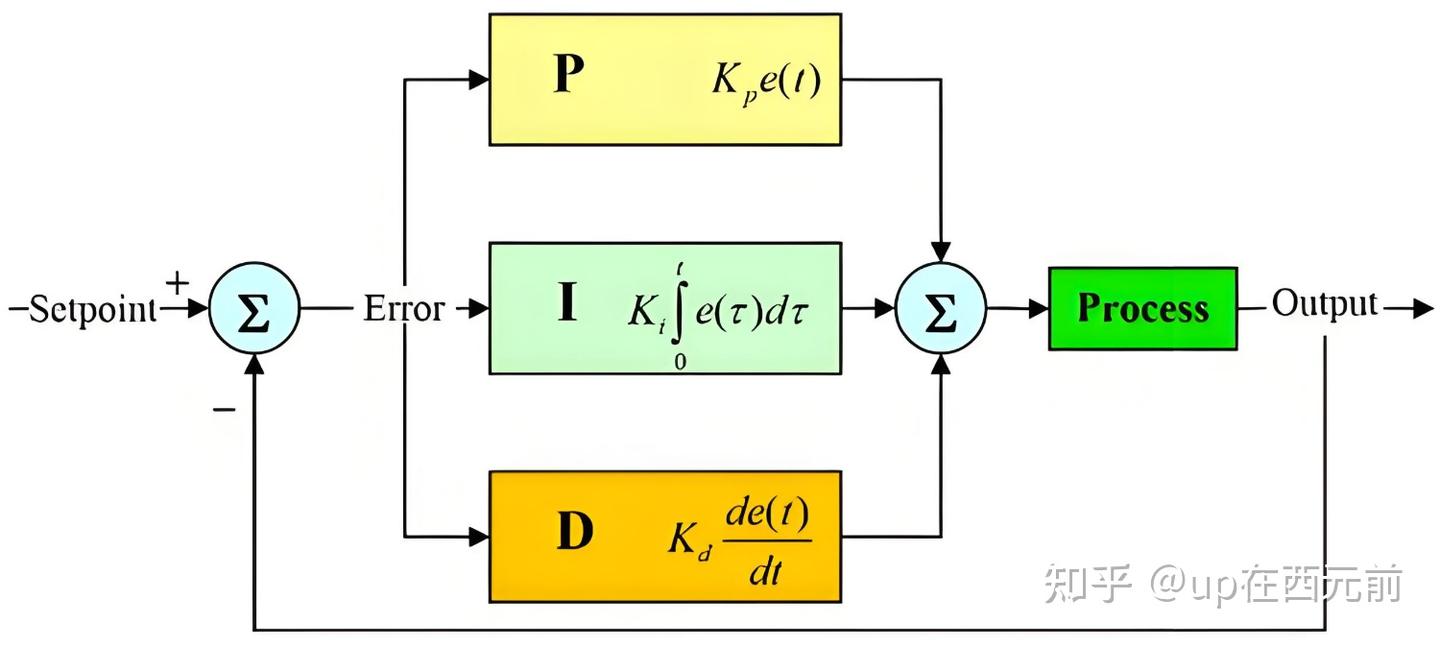
比例项的意义
积分项的意义
微分项的意义
一些花招
反馈抑制
积分限幅
微分先行
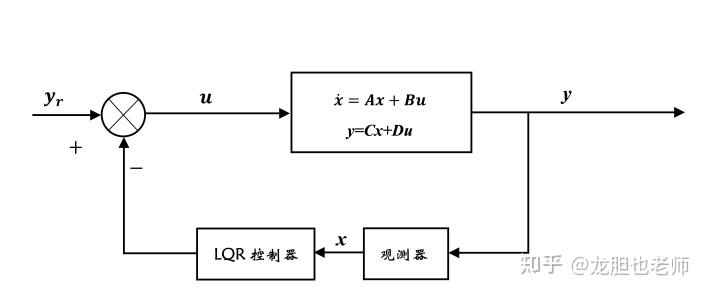
LQR调节器
LQR控制器设计 | Singularity-blog
LQR算法基本原理-CSDN博客
以倒立摆为例,学习设计LQR控制器 - Hexo
(52 封私信 / 80 条消息) 跳出课本看LQR控制,从公式到代码(上) - 知乎
最优控制公式推导(代数里卡提方程,李雅普诺夫方程,HJB方程)最优控制are-CSDN博客
LQR算法在运动控制中应用——LQR算法原理以及公式推导,参数说明,调参方式以及代码实现_lqr控制算法-CSDN博客
【控制入门】04-LQR控制算法 - 知乎
LQR (线性二次型调节器)的直观推导及简单应用 - 北极星! - 博客园
LQR控制基本原理(包括Riccati方程具体推导过程)lqr推导-CSDN博客
L 线性——线性时不变系统
Q 二次型——代价函数也就是能量的表现形式
R 调节器
有人写成这样
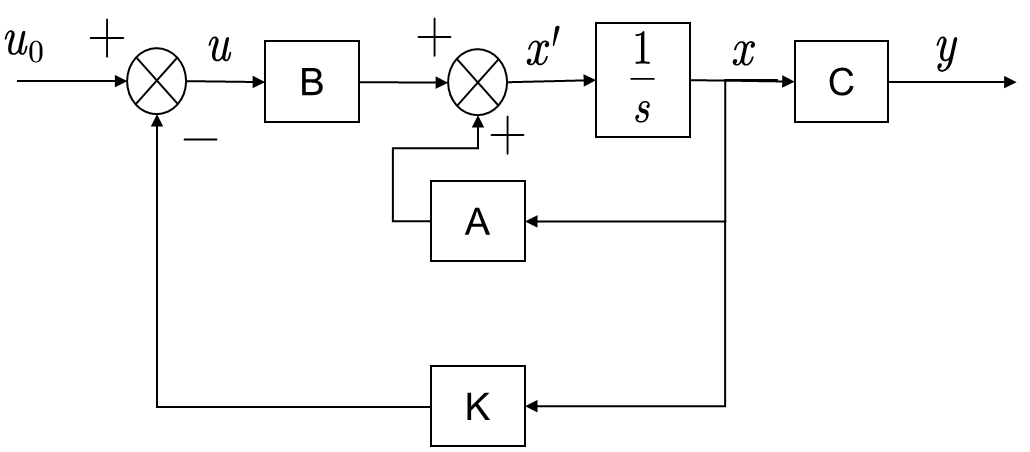
更好看的应该是这样
显然,这是对于用状态空间方程表示的线性时不变系统。
设计一个调节器,找到一个控制输入
参考动能和势能的二次型表示,来设计代价函数(泛函)。
其实可以参考朗道的《力学》,分析力学的能量和作用量的定义方法。这在最优控制中称为哈密顿函数法。
先说结论,得到的调节器是一个增益
推导:哈密顿-雅可比-贝尔曼方程
定义值函数
对于线性系统,上面的代价函数
其中,
说明:在本质上
是不可求导的,但是任意无限大的上界都是可以求导的,即
上为了更加严谨,一般写成价值函数为终端时刻的价值函数,即:
其中,
1.通过动态规划求解HJB方程
根据动态规划原理,值函数满足以下条件:
考虑
移项并除以
MPC
(57 封私信 / 80 条消息) MPC算法 - 知乎
局部路径规划属于MPC的某一种算法吗? - 知乎
(57 封私信 / 80 条消息) 通俗理解MPC(Model Predictive Control) - 知乎
对MPC原理和公式进行通俗解释及MATLAB代码实现-CSDN博客
机器人开发--MPC 模型预测控制 介绍_机器人mpc控制-CSDN博客
MPC, Pure_Pursuit, PID路径跟踪控制器设计与仿真_哔哩哔哩_bilibili
ROS中局部导航算法介绍及部分算法配置_ros 局部地图计算-CSDN博客
(57 封私信 / 80 条消息) ROS学习笔记-局部路径规划算法对比 - 知乎
ROS 导航,除了 DWA 和 TEB 还有没有其他选择?哔哩哔哩_bilibili
ROS 进阶课程-拥有一款全新的局部规划器 想要拥有这样一款全新的局部规划器。需要具备哪些基础呢。首先。你得懂一点 C 语言。第二。把这门 ROS 入门课程快速的过一遍。对 ROS 的导航架构有个大概的了解。然后。就可以开始局部规划器的进阶学习了。 好。那么这门进阶课程具体内容有哪些呢。咱们会先构建一个局部规划器的原始框架。然后慢慢往里边装填功能。一点一滴。逐步的进化。先是获取全局路径。实现一个简 - 抖音
DWA
(54 封私信 / 80 条消息) DWA(Dynamic Window Approach)局部路径规划算法详解及代码实现 - 知乎
DWA(dynamic window approach) - 是东东东啊 - 博客园
局部路径规划 DWA 算法完全解析(理论推导+代码实现,包你看懂!)-CSDN博客
(54 封私信 / 80 条消息) 局部路径规划属于MPC的某一种算法吗? - 知乎
基于DQN算法路径规划python dwa路径规划参数_mob6454cc77b8eb的技术博客_51CTO博客
走一步,看一步。
看什么?看速度。
速度多,猜轨迹。
轨迹好,挑哪个。

速度空间的确定
速度空间不是固定不变的,而是时变的,t 时刻的速度空间与 t + dt 时刻的速度空间是不同的,故将其称为动态窗口
速度空间,包含线速度的范围、角速度的范围……
速度限制
Vs 为机器人能够到达的所有矢量速度的集合;机器人受到最大最小线速度和角速度影响(实际上的速度范围由人为规定,在ROS的配置文件中修改)
加速度限制
由于加速度有一个范围限制,所以最大加速度或最大减速度一定时间内能达到的速度 ,才会被保留,表达式如下:
减速度限制
为了能在碰到障碍物前停下来,在最大减速度的条件下,速度满足以下条件:
速度采样

先在可行定义域内采集速度。
// update generic local planner params
base_local_planner::LocalPlannerLimits limits;
limits.max_vel_trans = config.max_vel_trans;
limits.min_vel_trans = config.min_vel_trans;
limits.max_vel_x = config.max_vel_x;
limits.min_vel_x = config.min_vel_x;
limits.max_vel_y = config.max_vel_y;
limits.min_vel_y = config.min_vel_y;
limits.max_vel_theta = config.max_vel_theta;
limits.min_vel_theta = config.min_vel_theta;
limits.acc_lim_x = config.acc_lim_x;
limits.acc_lim_y = config.acc_lim_y;
limits.acc_lim_theta = config.acc_lim_theta;
limits.acc_lim_trans = config.acc_lim_trans;
limits.xy_goal_tolerance = config.xy_goal_tolerance;
limits.yaw_goal_tolerance = config.yaw_goal_tolerance;
limits.prune_plan = config.prune_plan;
limits.trans_stopped_vel = config.trans_stopped_vel;
limits.theta_stopped_vel = config.theta_stopped_vel;
generator_.initialise(pos,
vel,
goal,
&limits,
vsamples_);
// if sampling number is zero in any dimension, we don't generate samples generically
if (vsamples[0] * vsamples[1] * vsamples[2] > 0) {
//compute the feasible velocity space based on the rate at which we run
Eigen::Vector3f max_vel = Eigen::Vector3f::Zero();
Eigen::Vector3f min_vel = Eigen::Vector3f::Zero();
if ( ! use_dwa_) {
// there is no point in overshooting the goal, and it also may break the
// robot behavior, so we limit the velocities to those that do not overshoot in sim_time
double dist = hypot(goal[0] - pos[0], goal[1] - pos[1]);
max_vel_x = std::maxmin(max_vel_x, dist / sim_time_), min_vel_x;
max_vel_y = std::maxmin(max_vel_y, dist / sim_time_), min_vel_y;
// if we use continous acceleration, we can sample the max velocity we can reach in sim_time_
max_vel[0] = std::min(max_vel_x, vel[0] + acc_lim[0] * sim_time_);
max_vel[1] = std::min(max_vel_y, vel[1] + acc_lim[1] * sim_time_);
max_vel[2] = std::min(max_vel_th, vel[2] + acc_lim[2] * sim_time_);
min_vel[0] = std::max(min_vel_x, vel[0] - acc_lim[0] * sim_time_);
min_vel[1] = std::max(min_vel_y, vel[1] - acc_lim[1] * sim_time_);
min_vel[2] = std::max(min_vel_th, vel[2] - acc_lim[2] * sim_time_);
} else {
// with dwa do not accelerate beyond the first step, we only sample within velocities we reach in sim_period
max_vel[0] = std::min(max_vel_x, vel[0] + acc_lim[0] * sim_period_);
max_vel[1] = std::min(max_vel_y, vel[1] + acc_lim[1] * sim_period_);
max_vel[2] = std::min(max_vel_th, vel[2] + acc_lim[2] * sim_period_);
min_vel[0] = std::max(min_vel_x, vel[0] - acc_lim[0] * sim_period_);
min_vel[1] = std::max(min_vel_y, vel[1] - acc_lim[1] * sim_period_);
min_vel[2] = std::max(min_vel_th, vel[2] - acc_lim[2] * sim_period_);
}
Eigen::Vector3f vel_samp = Eigen::Vector3f::Zero();
// 初始化速度迭代器:开始速度采样
VelocityIterator x_it(min_vel[0], max_vel[0], vsamples[0]);
VelocityIterator y_it(min_vel[1], max_vel[1], vsamples[1]);
VelocityIterator th_it(min_vel[2], max_vel[2], vsamples[2]);
轨迹预测
对于每个速度v,都有一个预测轨迹与其一一对应。例如差速轮底盘

例如全向底盘
令 Vy(t) = 0,则退化为差速运动模型,因此 ROS 自带的局部路径规划器使用上式计算
设 ∆t 为 0.1s,实际上预测机器人前向几秒内的所有状态,假设前向预测时间为 3s,则会预测 t ~ t + 3 s内的所有状态,即 t ~ t + ∆t ~ t + 2*∆t ~ …. ~ t + 3,相当于会预测出 t 时刻位置前 30 个点的位置,如下图所示

评价函数
这其实就是一个最基本的评价模型,朴素的归一化加权。
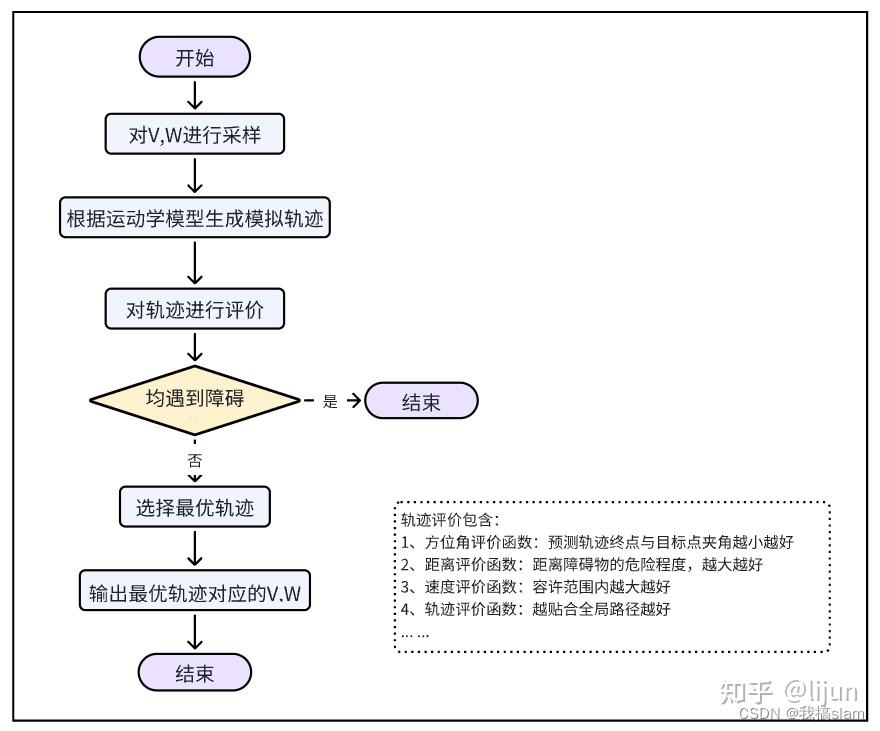
整个DWA就是采样、预测、评价三步走的决策迭代器。
对速度空间进行采样后,根据机器人运动学模型能够预测出多条轨迹,需要对这些轨迹进行评价,选取最优的轨迹,机器人根据最优轨迹对应的速度进行运动
- 方位角评价
heading(v,w):评价机器人在当前的设定的速度下,轨迹末端朝向与目标点之间的角度差距 - 避障评价
dist(v,w):主要的意义为机器人处于预测轨迹末端点位置时与地图上最近障碍物的距离,对于靠近障碍物的采样点进行惩罚,确保机器人的避障能力,降低机器人与障碍物发生碰撞的概率 - 快速性评价
velocity(v,w):为当前机器人的线速度,为了促进机器人快速到达目标 - α、β、γ、σ 为权重系数
采集到各种速度方案后,记得对同种指标进行归一化处理。
再进行赋权,得到评价函数。DWA 算法对轨迹的评价函数一般如下所示
原文中提到方位角评价函数对轨迹规划的影响较大,太大易陷入局部最优解,太小能更好地避障,但路径有点长,效率有些低

由上图我们可以看到绿色的线是全局规划的路线,蓝色的短线表示局部规划的路线

ROS参数:dwa_local_planner_params.yaml
ROS导航仿真使用dwa做规划器的部分参数调试心得 - 知乎
DWA所有参数 | 沉默杀手
dwa_local_planner_params.yaml解读_diff drive robot, there is only one sample-CSDN博客
DWA导航算法参数调整记录_dwa参数-CSDN博客
平动空间的约束如图,单位m/s(加速度会让方框和圆环都“膨胀”acc_lim*sim_time)
转动空间的约束如下
- max_rot_vel: 0.25 最大旋转速度的绝对值.
- min_rot_vel: 0.1 最小旋转速度的绝对值.
- acc_lim_theta: 2.0 机器人的极限旋转加速度,单位为 rad/sec^2
前向模拟参数
- sim_time: 1.7 前向模拟轨迹的时间间隔,单位s
- vx_samples: 3 样本数 (integer, default: 3)
- vy_samples: 10 (integer, default: 10)
- vth_samples: 20 角速度的样本数 (integer, default: 20)
目标判定参数(防止机器人一直原地蛄蛹)
- trans_stopped_vel: 0.1 机器人被认为已经“停止”状态时的平移速度。如果机器人的速度低于该值,则认为机器人已停止。单位为 m/s
- theta_stopped_vel 同理
- yaw_goal_tolerance: 0.2 到达目标点时偏行角允许的误差,单位弧度.
- xy_goal_tolerance: 0.22 到达目标点时,在xy方向与目标点的距离误差.
- latch_xy_goal_tolerance: false 若设置为true,如果到达容错距离内,机器人就会原地旋转,即使转动会跑出容错距离外.
障碍判定参数
- stop_time_buffer: 0.2 0.2 - 为防止碰撞,机器人必须提前停止的时间长度
路径评分参数,呼应
- path_distance_bias: 32.0 控制器靠近给定路径的权重 (double, default: 32.0)
- goal_distance_bias: 24.0 控制器尝试达到其本地目标and控制着速度的权重。(double, default: 24.0)
- occdist_scale: 0.01 控制器尝试避免障碍物的权重 (double, default: 0.01)
调试参数
- publish_traj_pc : true 将规划的轨迹在RVIZ上进行可视化
- prune_plan: false 机器人前进时,是否清除身后1m外的轨迹.默认是true
- publish_cost_grid_pc: true 将代价值进行可视化显示 (bool, default: false),是否发布规划器在规划路径时的代价网格.如果设置为true,那么就会在~/cost_cloud话题上发布sensor_msgs/PointCloud2类型消息
- holonomic_robot: false 是否为全向机器人。 值为false时为差分机器人; 为true时表示全向机器人
特殊参数
DWAPlannerROS:
sim_granularity # 看官方文档
angular_sim_granularity # 看官方文档
# Trajectory Scoring Parameters 轨迹评分参数
forward_point_distance: 0.325 # 0.325 - 以机器人为中心,额外放置一个计分点的距离
scaling_speed: 0.25 # 0.25 - absolute velocity at which to start scaling the robot's footprint
#开始缩放机器人足迹时的速度的绝对值,单位为m/s。
#在进行对轨迹各个点计算footprintCost之前,会先计算缩放因子。如果当前平移速度小于scaling_speed,则缩放因子为1.0,否则,缩放因子为(vmag - scaling_speed) / (max_trans_vel - scaling_speed) * max_scaling_factor + 1.0。然后,该缩放因子会被用于计算轨迹中各个点的footprintCost。
# 参考:https://www.cnblogs.com/sakabatou/p/8297479.html
#亦可简单理解为:启动机器人底盘的速度.(Ref.: https://www.corvin.cn/858.html)
max_scaling_factor: 0.2 # 0.2 - how much to scale the robot's footprint when at speed. 最大缩放因子。max_scaling_factor为上式的值的大小。
# 振荡预防参数
oscillation_reset_dist: 0.05 # 0.05 - 机器人必须运动多少米远后才能复位震荡标记(机器人运动多远距离才会重置振荡标记)
# Global Plan Parameters
#prune_plan: false
#机器人前进是否清除身后1m外的轨迹.
TrajectoryPlannerROS
唯一的DWA与“TrajectoryPlanner”的不同之处,在于如何对机器人的控制空间进行采样。在给定机器人的加速度极限的情况下,TrajectoryPlanner在整个前向模拟周期内从可实现的速度集合中进行采样,而DWA在给定机器人的加速度极限的情况下仅针对一个模拟步骤从可实现的速度集合中进行采样。在实践中,我们发现DWA和轨迹展示在我们的所有测试中都具有相同的性能,并建议使用DWA来提高效率,因为其样本空间更少。
TEB
(57 封私信 / 80 条消息) TEB(Time Elastic Band)局部路径规划算法详解及代码实现 - 知乎